Mis en ligne le 13/01/22
Lorsqu’on entend dans la même phrase les mots « data » et « médias », de très nombreuses images nous apparaissent à l’esprit. On imagine des dizaines de terras de données utilisées par les médias les plus influents afin de comprendre avec précision quel est leur public, pour leur proposer le contenu le plus adapté et faire la plus grande audience possible. C’est en effet un aspect particulièrement important de ce couple data-média et nous nous y intéresserons dans un prochain article.
Néanmoins, il est intéressant de prendre le sujet dans l’autre sens. La nature de la data peut en effet être si différente que ce serait une erreur de ne pas considérer les données que l’on peut extraire des médias eux-mêmes. Plusieurs preuves permettent de témoigner de cette possibilité de production non seulement de « data », mais également de « big data ».
Tout cela semble impossible à quantifier, tant la production paraît immense. Utiliser des mots tels que « beaucoup » n’est certainement pas très scientifique, et j’ai moi-même eu du mal à rédiger cette petite introduction : il est tout bonnement impossible de comprendre et de saisir l’ampleur des données qu’il est possible d’extraire des médias sans recourir à un travail de statisticien. La formation dispensée à l’ENSAI offre ainsi les outils permettant de comprendre tout cela.

De fait, je me suis penché sur un site en particulier, qui propose effectivement une analyse des médias. Deux options sont disponibles. La première permet de vérifier la fiabilité d’un site, et permet simplement en copiant-collant le lien de l’article de vérifier s’il provient d’un site de confiance. La deuxième est un moteur de recherche, qui, à partir de quelques mots clés, permet de trouver à la fois des éléments provenant de sources fiables, et de sources qui ne le sont pas.
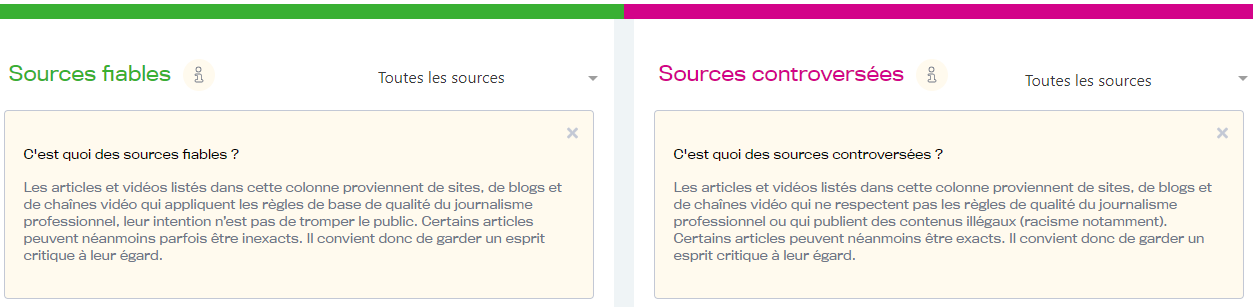
Ainsi, de petites indications permettent de comprendre ce qui accorde à l’article cette place dans les « Sources controversées » : complotisme, intolérance et piège à clic sont les arguments les plus récurrents. Ce site permet ainsi au lecteur de travailler son esprit critique et l’aiguille dans le choix des sources qui méritent sa confiance.
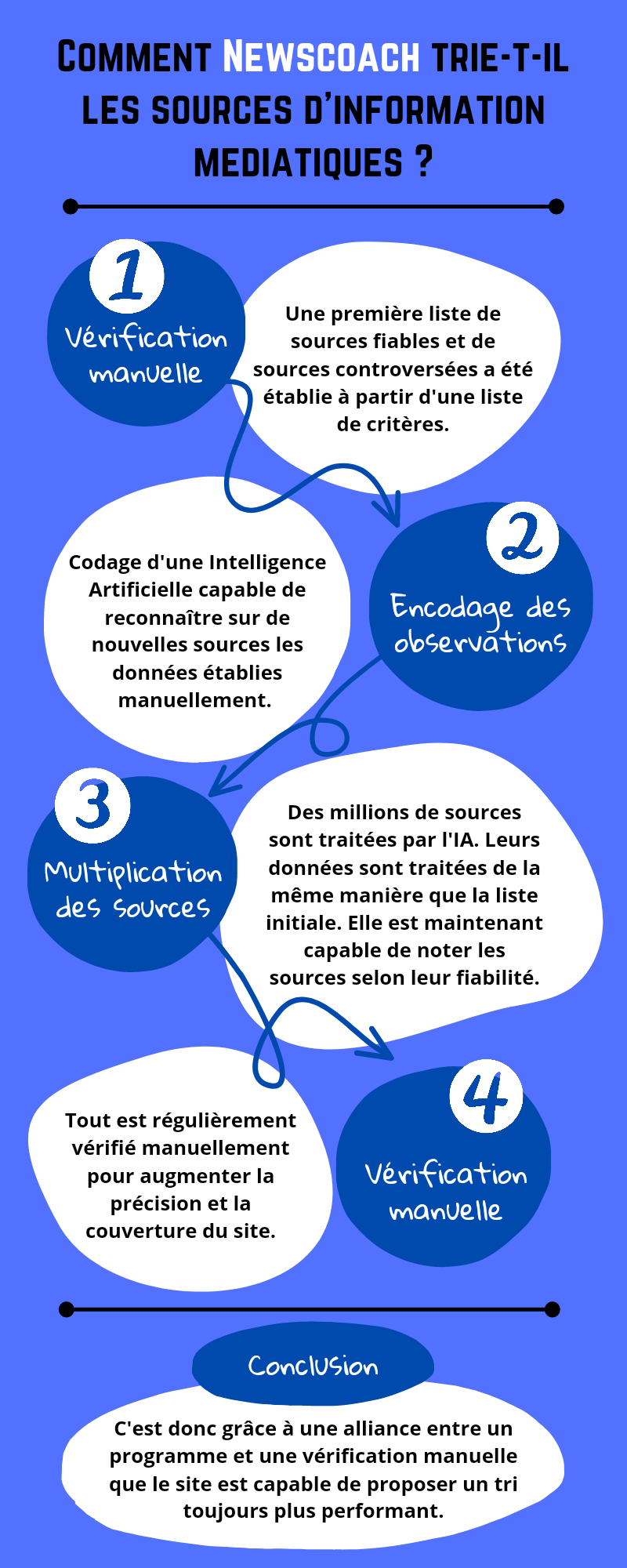
Si cet objectif d’honnêteté journalistique, de médias plus « justes » est tout à fait louable, ce qui nous intéresse est plutôt la façon dont ces informations sont triées. En effet, s’il est évident que le « tri » effectué par le site n’est pas parfait, il obéit tout de même à une méthodologie précise et à des règles pré-établies. J’ai ainsi décidé de contacter le créateur du site, qui m’a permis de comprendre comment tout cela fonctionnait.